How to Convert VSAM to AWS dynamoDb?
- Background
- What is Amazon DynamoDB
- What is IBM VSAM (Virtual Sequential Access Method)
- What are DynamoDB Partitions and How do they work?
- What are CIs (control interval) and CAs (control area) in VSAM & how does CI/CA splits work?
- VSAM files Versus DynamoDB
- Migrating VSAM files/DB2 tables to DynamoDB
- Additional Examples and Further Reading
- Thank you
(TL;DR)
I wanted to explain the reasoning behind the blog for two very specific reasons.
- My struggle with arriving at the title of the
blog to make it relevant to the audience. If I had just chosen the title for
the mainframe OR the COBOL or the VSAM, a lot of mainframe fanatics like myself
would have pooh-poohed this blog. This is the reason I included all three and
strategically included them with slashes. - I wanted to provide our mainframe programmers a
way into the cloud by leading them into something like -NoSQL databases –
considered really complex for us relationally minded mainframe technologists
and provide them a way to equate it with something that we have worked on for
years.
This idea came me as I was preparing for my AWS Solutions Architect exam and I have been meaning to write this as soon as it struck me to derive a parallels between the two completely disconnected paradigms.
Amazon DynamoDB is a fully managed NoSQL database service that supports key-value and document data models, and enables developers to build modern, serverless applications that can start small and scale globally to support petabytes of data and tens of millions of read and write requests per second. It automatically manages the data traffic of tables over multiple servers and maintains performance. It also relieves the customers from the burden of operating and scaling a distributed database. Hence, hardware provisioning, setup, configuration, replication, software patching, cluster scaling, etc. is completely managed by AWS.
DynamoDB database is made of tables, items and attributes. Each table is a collection of data consisting of zero or more items and each item can consist of one or several atomic attributes identifying the item.
Primary Keys
When you create a table, in addition to the table name, you must specify the primary key of the table. The primary key uniquely identifies each item in the table, so that no two items can have the same key.
DynamoDB supports two different kinds of primary keys:
Partition key – A simple primary key, composed of one attribute known as the partition key. DynamoDB uses the partition key’s value as input to an internal hash function. The output from the hash function determines the partition (physical storage internal to DynamoDB) in which the item will be stored.
Partition key and sort key – Referred to as a composite primary key, this type of key is composed of two attributes. The first attribute is the partition key, and the second attribute is the sort key.
DynamoDB uses the partition key value as input to an internal hash function. The output from the hash function determines the partition (physical storage internal to DynamoDB) in which the item will be stored. All items with the same partition key value are stored together, in sorted order by sort key value.
In a table that has a partition key and a sort key, it’s possible for two items to have the same partition key value. However, those two items must have different sort key values.
There are many features of DynamoDB. Instead of reproducing the documentation I am listing some of the links I have found really useful from AWS as well as other sources.
Performance at scale
- Key Value &
Document Data Models - Microsecond
latency with DAX – DynamoDB Global Accelerator - Multi-Region
replication with Global Tables - Real-time data
processing with DynamoDB streams
Serverless
It’s been proven that DynamoDB performs better as load increases.
- DynamoDB
Streams & Lambda Triggers - Complex
Workflow support with DynamoDB ACID transactions - Encryption at
rest - Point-in-time
recovery for DynamoDB - On Demand
Backup & Restore
What is IBM VSAM (Virtual Sequential Access Method)
From IBM’s definition of a mainframe system at its IBM knowledge center –
A mainframe is what businesses use to host the commercial databases, transaction servers, and applications that require a greater degree of security and availability than is commonly found on smaller-scale machines.
I have no statistics to prove but a large amount of financial, banking, brokerage, travel and food processing companies continue to use IBM mainframes to securely house, process and manage data. However, a lot of this landscape is changing with cloud and innovations around hybrid cloud architectures and design patterns. There are several innovations that IBM is working on to etch its place and solidify it on the cloud side. More on this later, at this time, I wanted to focus on the virtual storage access methods a.k.a VSAM datasets and how close some of the design features of VSAM datasets are with AWS DynamoDB.
To read more about IBM mainframe data storage types and concepts around it please see –
· z/OS Storage Constructs: Files Systems, datasets etcetera
· Dataset Access Methods on IBM Mainframes
· Dataset Record Formats on IBM Mainframes
A lot of information is available on IBM’s zOS concepts site regarding VSAM. The virtual storage access method can refer to a specific dataset type as well as the access method for managing the various dataset types. There are four kind of VSAM dataset types –
| VSAM Type | Storage | Usage |
| KSDS (Key Sequence Data Set) | Records are organized using key fields and can be accessed or new records inserted using key fields. The data can be accessed sequentially or randomly by explicitly specifying the key values in the START key (ExclusiveStartKey). | IBM’s IMS System |
| ESDS (Entry Sequence Data Set) | Records are organized in sequential order & data is accessed sequentially | IBM’s IMS & DB2 System |
| RRDS (Relative Record Data Set) | This format allows accessing records by a record (#item) number. The data can be accessed randomly | |
| LDS (Linear Data Set) | This format allows to store data in byte stream data set | IBM DB2 |
VSAM files can be processed or used in a program ONLY after the definition of the file is in place using IBM’s access method services (AMS). Here is a sample of a KSDS VSAM CLUSTER definition including index and data components.
| VSAM FILE TYPE | Sequential Access | Random Access | Dynamic Access |
| VSAM sequential (ESDS) | Yes | No | No |
| VSAM indexed (KSDS) | Yes | Yes | Yes |
| VSAM relative (RRDS) | Yes | Yes | Yes |
| Access Mode in File Control (when Allowed) | ACCESS IS SEQUENTIAL | ACCESS IS RANDOM | ACCESS IS DYNAMIC |
| Key Access Pattern | Initiate Reading of KSDS VSAM with a START KEY | Pass Exclusive Start Keys when reading VSAM | It combines features of sequential & random access of VSAM file |
Defining a VSAM cluster
Here is a how a VSAM cluster is defined:

What are DynamoDB Partitions and How do they work?
A partition is an allocation of storage for a table, backed by solid-state drives (SSDs) and automatically replicated across multiple Availability Zones within an AWS region.
Data in DynamoDB is spread across multiple DynamoDB partitions. As the data grows and throughput requirements are increased, the number of partitions are increased automatically. DynamoDB handles this process in the background.
When we create an item, the value of the partition key (or hash key) of that item is passed to the internal hash function of DynamoDB. This hash function determines in which partition the item will be stored. When you ask for that item in DynamoDB, the item needs to be searched only from the partition determined by the item’s partition key.
The internal hash function of DynamoDB ensures data is spread evenly across available partitions. This simple mechanism is the magic behind DynamoDB’s performance.
Limits of a Partition
DynamoDB Partition Size Limit = 10 GB
DynamoDB Item Size Limit = 400kb
Total items stored in a partition = 10GB/400KB = 10485760KB/400KB = 26214 items
Each partition can support a maximum of 3,000 read capacity units (RCUs) or 1,000 write capacity units (WCUs) irrespective of the size of the data.
When and How Partitions Are Created
When a table is first created, the provisioned throughput capacity of the table determines how many partitions will be created. The following equation from the DynamoDB Developer Guide helps you calculate how many partitions are created initially.
InitialPartitions (rounded up) = ( readCapacityUnits / 3,000 ) + ( writeCapacityUnits / 1,000 )
Which means that if you specify RCUs and WCUs at 3,000 and 1,000 respectively, then the number of initial partitions will be
( 3_000 / 3_000 ) + ( 1_000 / 1_000 ) = 1 + 1 = 2.
Suppose you are launching a read-heavy service in which a few hundred authors generate content and a lot more users are interested in simply reading the content. So, you specify RCUs as 1,500 and WCUs as 500, which results in one initial partition ( 1_500 / 3000 ) + ( 500 / 1000 ) = 0.5 + 0.5 = 1.
Subsequent Allocation of Partitions
Let’s go on to suppose that within a few months, the application becomes very popular and lots of authors are publishing their content to reach a larger audience. This increases both write and read operations in DynamoDB tables.
As a result, you scale provisioned RCUs from an initial 1500 units to 2500 and WCUs from 500 units to 1000 units.
(2500 / 3000) + (1000 / 1000) = 1.83 = 2
The single partition splits into two partitions to handle this increased throughput capacity. All existing data is spread evenly across partitions.
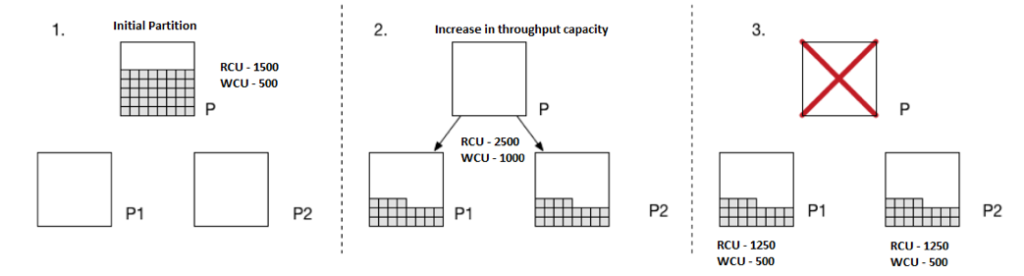
Another important thing to notice here is that the increased capacity units are also spread evenly across newly created partitions. This means that each partition will have 2_500 / 2 => 1_250 RCUs and 1_000 / 2 => 500 WCUs.
When Partition Size Exceeds Storage Limit of DynamoDB Partition
With time, the partitions get filled with new items, and as soon as data size exceeds the maximum limit of 10 GB for the partition, DynamoDB splits the partition into two partitions.
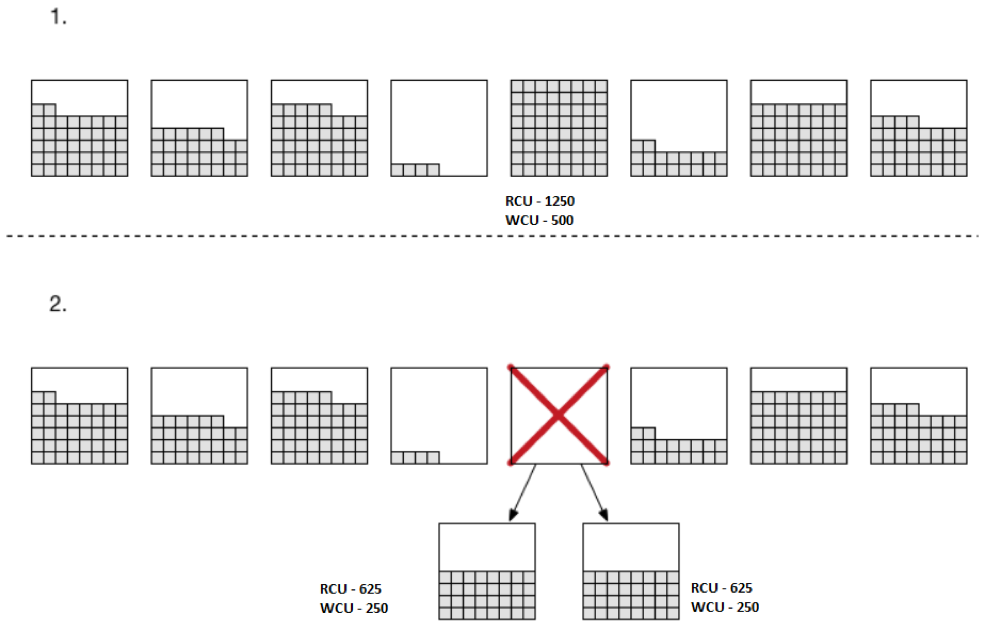
The splitting process is the same as shown in the previous section; the data and throughput capacity of an existing partition is evenly spread across newly created partitions.
How Items Are Distributed Across New Partitions
Each item has a partition key, and depending on table structure, a range key might or might not be present. In any case, items with the same partition key are always stored together under the same partition. A range key ensures that items with the same partition key are stored in order.
There is one caveat here: Items with the same partition key are stored within the same partition, and a partition can hold items with different partition keys — which means that partition and partition keys are not mapped on a one-to-one basis. Therefore, when a partition split occurs, the items in the existing partition are moved to one of the new partitions according to the mysterious internal hash function of DynamoDB.
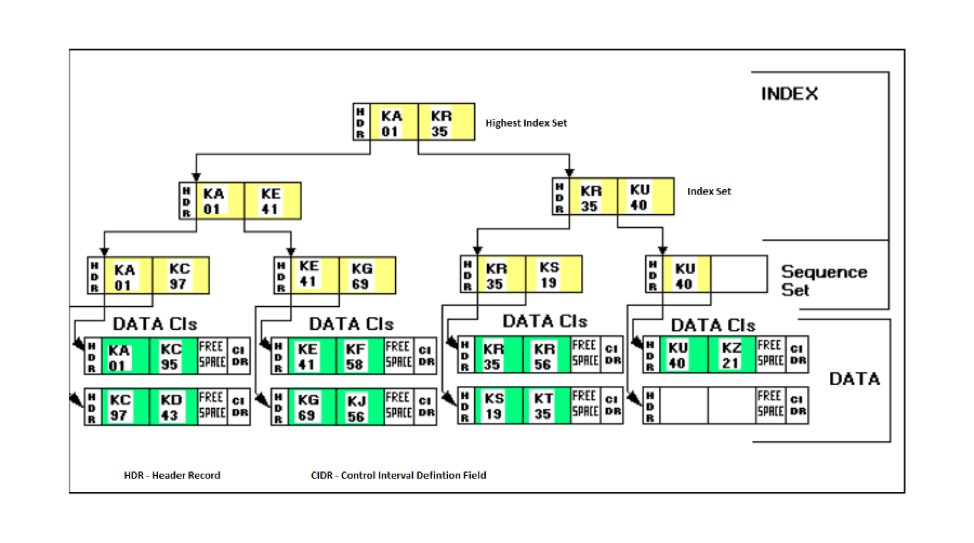
What are CIs (control interval) and CAs (control area) in VSAM & how does CI/CA splits work?
Visually here is how the VSAM cluster looks like on the mainframe systems.
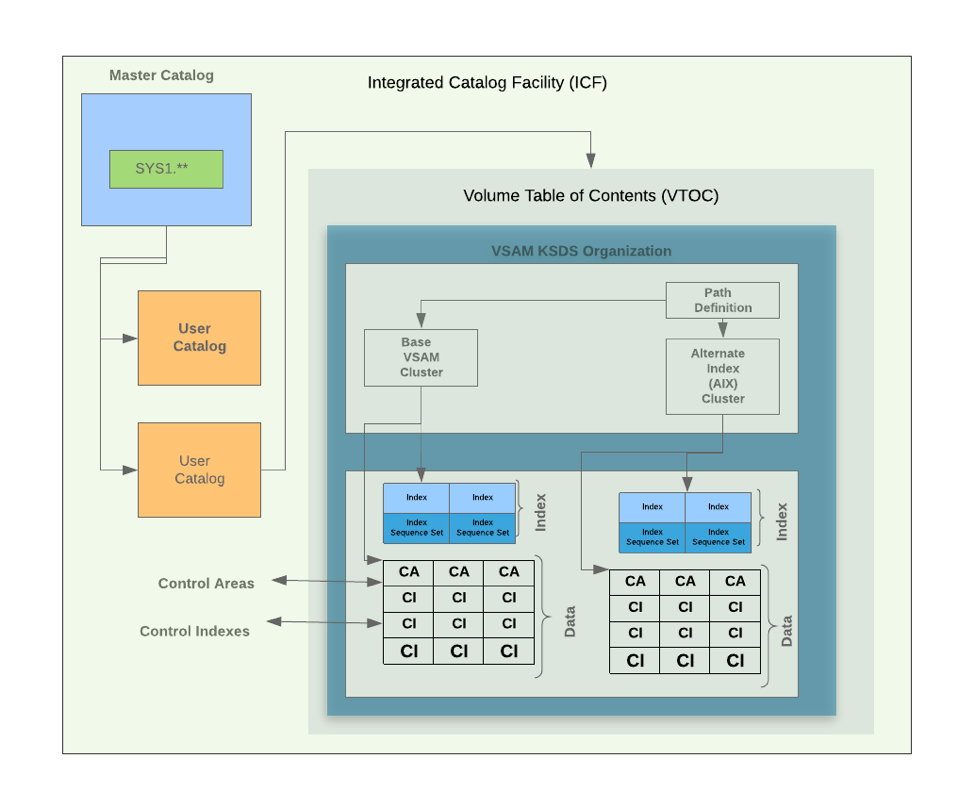
A control interval [CI] is the VSAM unit of I/O and the structure around the logical records an application manipulates. Choosing a CI size requires understanding many factors and is generally a trade-off between saving DASD by using large blocks vs. using smaller CIs for potentially better online performance. The application record length also matters because VSAM has discrete CI sizes to pick from, which rarely accommodate the records with no space left over. A Control Area (CA) is a logical grouping of CIs, usually set at a cylinder. The programmer has no direct control over CA size. Instead, VSAM picks a CA size based on the data set’s allocation units.
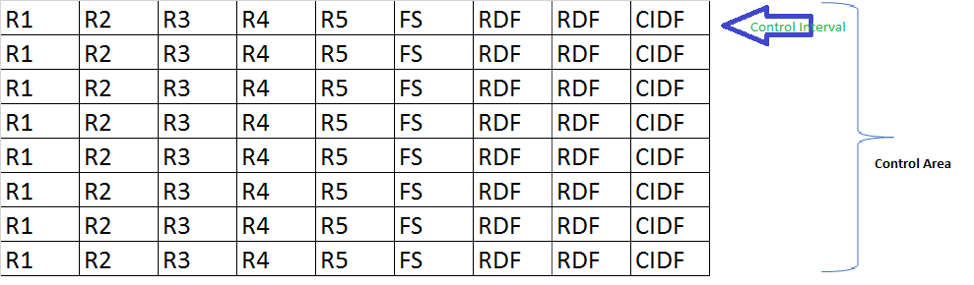
R1-R5 – Records in the control-interval (CI)
FS – Free Space on the CI used for expansion
RDF – Record definition fields describing the length of the records in CI
CIDF – Control information definition fields.
In a cluster definition, the CI free space is expressed as the percentage of bytes to leave empty when a cluster initially loads. For CAs, the free space is the percentage of empty CIs left at the end of the area.
As VSAM loads a cluster, it lays the records end to end into an empty CI until it determines the next record will leave less than the minimum amount of free space. VSAM then proceeds to put records into the next available CI. This continues until the number of remaining free CIs reaches the CA free space limit and VSAM moves on to the next CA.
Each CI has its prescribed amount of free space specified in the cluster’s definition. For instance, specifying 10 percent free space for a 4K data CI VSAM will reserve at least 409 free bytes. At the end of each CA are several empty CIs, depending on the CA free space in the definition. For example, a data component with 90 CIs per CA and a 10 percent CA free space will have nine free CIs per CA. The actual number of free bytes in a CI is indeterminate because it depends on the size of the records going into the CI at the time. But VSAM guarantees there should never be less free space than what’s specified in the CI free space definition.
Free space applies only at data set loading time. After that, VSAM uses the reserved free space when the application adds records while maintaining the records in key sequence in a CI. If there isn’t enough free space in the CI, VSAM divides the records more or less evenly and leaves half of them in the original CI. The other half goes into one of the empty CIs left at the end of the CA. This is called a CI split. If there aren’t any free CIs, VSAM has to go through a CA split. To accomplish this, VSAM moves half of the CIs in the CA to empty space at the end of the cluster. The other half of the CIs stay in the original CA. With some clusters having upward of 90 CIs per CA, you can see where this turns into a lot of work.
| Virtual Sequential Access Method (VSAM) | DynamoDB |
| VSAM datasets are defined as clusters | DynamoDB’s highest level of data organization is a partition. |
| VSAM clusters contains the data as well as the index components | DynamoDB’s base table contains the partition key & SORT key (Local secondary indexes) and additional attributes identifying a table item. |
| VSAM Path definitions are definitions of alternate indexes | DynamoDB GSI’s are alternate/secondary indexes |
| Alternate Indexes (path definitions) are defined after base VSAM cluster and key definitions are made | DynamoDB GSI’s are provisioned after the base table is created |
| Alternate indexes is virtualization of the same VSAM data to be accessed by different key and serve a distinct access pattern | DynamoDB GSI’s are definition of keys different from base table to serve a distinct access pattern |
| VSAM control interval (CI) and control area (CA) are defined during the base cluster definition .DEFINE CLUSTER (NAME(VSAM.FILE.NAME) – BLOCKS(number) – VOLUMES(volume-serial) – Volume on which the cluster resides [INDEXED / NONINDEXED / NUMBERED / LINEAR] – Type of dataset RECSZ(average maximum) – Average & maximum record size [FREESPACE(CI-Percentage, CA-Percentage)] – Free space definition CISZ(number) – Size of control interval | DynamoDB partitions are defined based on the provisioned throughput capacity using the below logic – InitialPartitions (rounded up) = ( readCapacityUnits[RCU] / 3,000 ) + ( writeCapacityUnits[WCU] / 1,000 ) Each partition can support a maximum of 3,000 read capacity units (RCUs) or 1,000 write capacity units (WCUs) irrespective of the size of the data. |
| The CI size definition of an alternate index is usually different from the base table | The provisioned RCU and WCU of the GSI is different from the base table |
| VSAM control interval (CI) and control area (CA) splits occur to accommodate new data into the cluster by utilizing the free space allocated during cluster definition | DynamoDB partitions occur when provisioned RCUs and WCUs are increased to accommodate increase in traffic and load or when the table partition reaches the 10GB limit. |
| The RLS (record level sharing) feature of VSAM allows it to be shared across different logical partitions (LPARs) on an MVS system | DynamoDB tables are replicated across at least three availability zones in a region and based on the usage of consistent read parameter during I/Os you can get the most current or stale data when reading the table. |
| Based on initial definition of the cluster, its possible for the VSAM cluster to undergo CI size changes during file reorganizations | Due to insufficient provisioned capacity of RCU and WCUs, a DynamoDB table read or writes can create hot partitions leading to incorrect results. |
Migrating VSAM files/DB2 tables to DynamoDB
If you understand DynamoDB and are comfortable with the simplicity involved in determining the complex access patterns, then it will become apparent to you how easier it is de-normalize the data present in plethora of your VSAM files and design a single DynamoDB table that contains all your data.
The same logic can be used for DB2 tables. However, I wanted to touch the VSAM and flat (physical sequential – PS) files first due to a virtualization and accessibility struggle that organizations are going through in an effort to make data that exists on mainframe VSAM & flat files accessible to distributed applications.
IBM’s native SQL stored procedures have simplified how DB2 data is virtualized to distributed applications. The REST (Representative State Transfer) native API implemented in DB2 V 12 is a light weight interface using HTTP POST / GET request handling to drive SQL and stored procedures, with the result sets being returned in JSON (Java Script Object Notation) format.
Here is my very high level attempt at re-thinking data model of a trading application spread across multiple VSAM files with varying fields and file lengths.
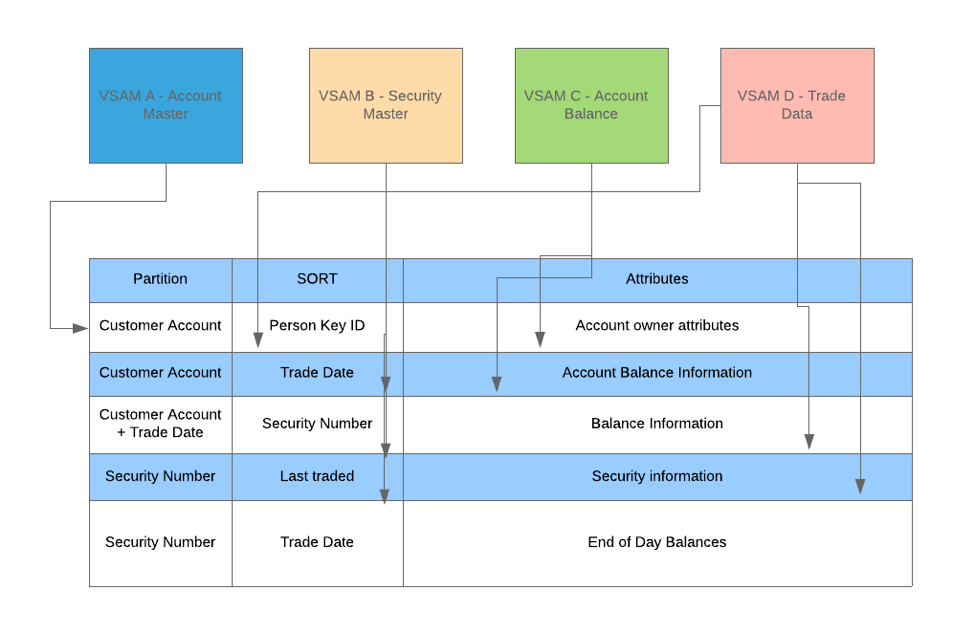
There are several use cases & examples available on the web for adopting single table design patterns using DynamoDB –
Advanced design patterns using DynamoDB – Reinvent Session
Data Modeling with DynamoDB – Reinvent Session
Some of the examples shared during the session will help you understand the NoSQL Database systems layer by layer.
Additional Examples and Further Reading
https://www.dynamodbguide.com/about/
DB2 – NSPS –
Future of computing
Rocket Software – VSAM Virtualization
If there are any questions, concerns, suggestions or feedback please feel to email me or leave a comment under the blog. It will help me and other users!!
Thank you!
Also read Cloud 101 for Mainframe Developers
AUTHOR: Mukesh is a cloud enthusiast with a bias for AWS. You can reach him on LinkedIn.
Announcement from ReviewNPrep: Our Marketplace is live now. Check out AWS Solutions Architect SAA-C02 Practice exam with over 800 questions to help you pass this exam.

[…] Practical Comparisons of DynamoDB and VSAM […]
[…] Practical Comparisons of DynamoDB and VSAM […]
[…] Practical Comparisons of DynamoDB and VSAM […]
Very well written. Easy to understand the concept. Thank you for sharing me the blog details..
Very well written, easy to understand, to the point article. Thanks a ton for such great stuff.